LexiTR
is an innovative suite of tools specifically designed to enhance the analysis and understanding of the Turkish language.
A Turkish Lexicon Toolkit by TS Corpus
LexiTR is designed to fill the gap in Turkish vocabulary studies. It features an innovative suite of tools specifically designed to enhance the analysis and understanding of the Turkish language. LexiTR serves a rich dataset of approximately +190 million words spanning four genres
academic papers
social media
fictional texts
informative texts
| Genre | Percentage | Word Count |
|---|---|---|
| Academic | 7.94% | 15.365.389 |
| Social Media | 19.87% | 38.461.199 |
| Fictional | 25.78% | 49.908.578 |
| Informative | 46.41% | 89.835.094 |
| TOTAL: | 100%| 193.570.260 | |
Distribution of LexiTR Data
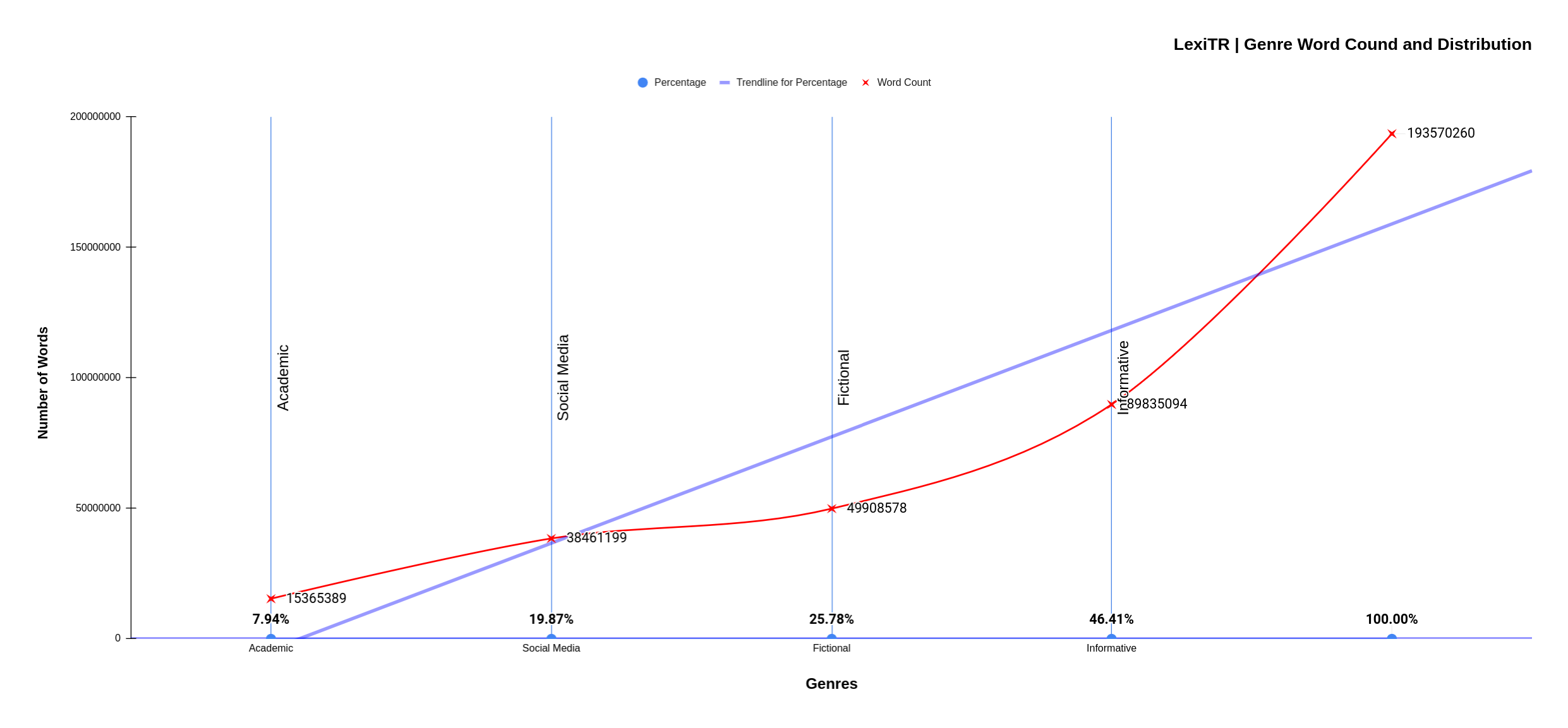
This diversity of genres and the size of the corpus ensures that users can access and analyze language patterns and usage across different styles and contexts.
Each tool presented under LexiTR shares the same data source to set a valid research background.
Key Features of LexiTR:
- Collocation Dictionary: Dive deep into the way words co-occur in natural language,
exploring the associations and combinations that define Turkish syntax and usage.
- Frequency Tool: Gain quantitative insights with our
sophisticated frequency analysis, enabling you to determine how often words
appear across different genres, aiding in everything from linguistic research to
practical application in language learning.
LexiTR is more than just a toolset—it's an essential resource for educators, researchers,
linguists, and enthusiasts of the Turkish language who are looking to deepen their
understanding of linguistic patterns and improve their applications of the language in varied fields.
Whether you're crafting educational curriculum, conducting linguistic research, or simply indulging in the rich linguistic tapestry of Turkish, LexiTR provides the data-driven support you need to succeed.
Whether you're crafting educational curriculum, conducting linguistic research, or simply indulging in the rich linguistic tapestry of Turkish, LexiTR provides the data-driven support you need to succeed.